Apples and Oranges? Comparing Human and AI Bids in Experimental Auctions for Food Products
Carola Grebitus, C-FARE Board Member (Arizona State University); Jay Corrigan (Kenyon College); and Matthew Rousu (Susquehanna University)
Can ChatGPT and other AI models replicate human bidding behavior in experimental auctions? And if so, what does that mean for future economic research?
Artificial intelligence (AI) is an increasingly popular tool for economics research. This raises questions about whether it can complement—or perhaps even replace—human participants in economics experiments. We explored this possibility by asking large language models (LLMs) like ChatGPT, Claude, and Gemini to stand in for people in experimental auctions used to measure consumer willingness to pay.
Experimental auctions are a well-established technique for estimating the value people derive from different food attributes—like organic labels, fair trade certification, or local sourcing. But experimental auction studies are costly and time-consuming, often requiring hundreds of participants and costing tens--or sometimes even hundreds--of thousands of dollars. If AI could accurately mimic human bidding behavior, it could make this type of research faster and cheaper.
We asked three LLMs—ChatGPT-4o, Claude 3.7 Sonnet, and Gemini 2.0 Flash—to bid in two experiments we had previously conducted with human participants. One was an experimental auction from the United States where participants bid on coffee with different sustainability labels, and the other was from Germany where participants bid on apples and wine labeled based on how far they were transported.
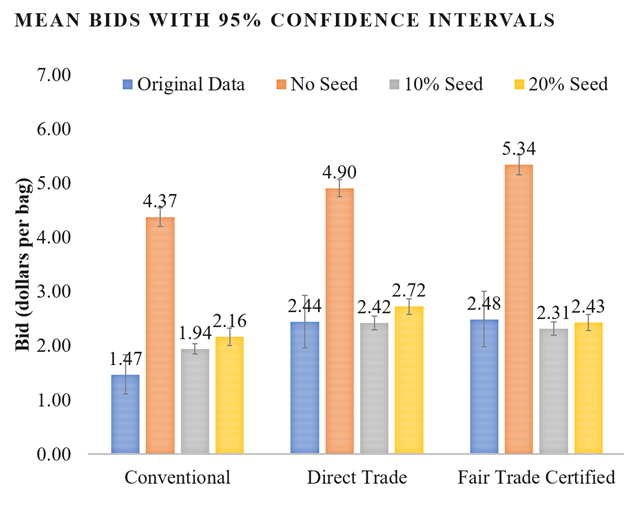
When given only the experiment’s instructions and demographic data about participants, the LLMs didn’t perform well. The models’ bids deviated dramatically from human results, producing average bids that were double or even triple the original results. But when we ‘seeded’ the models by providing a small sample of real bids (10 to 20 percent of the original data) as a reference, the AI’s performance improved dramatically. With that “training,” the AI-generated bids closely matched human bidding behavior in both experiments (see Figure 1).
Our results suggest that LLMs can’t (yet) replace human participants in valuation studies. That said, LLMs may be a valuable complement. For example, researchers could use AI-generated data to pilot experimental designs, testing the clarity of study instructions. Or researchers could use AI to explore markets for goods that don’t yet exist or that are ethically sensitive—such as estimating demand for products that can’t legally be sold. LLMs might also be used to extend results from an existing human sample. For instance, if a study was conducted in a specific region or using a convenience sample, researchers could use the LLM to generate data for a representative, nationwide sample.
Based on our tests, we believe that LLMs are a promising complement to human subjects, not a replacement. While our research highlights both the current limits and future potential of AI in applied economics, as models continue to evolve, the question may shift from whether to use AI in experimental research to how to use it responsibly.
Figure 1. Can AI “hack” human behavior? Comparing Chat GPT coffee bids to data from shoppers
Further readings: Corrigan, J.R., Grebitus, C., and M.C. Rousu (2025): On the Usefulness of Using Current LLMs for Experimental Auction Valuation (April 14, 2025). Available at Social Science Research Network-SSRN: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=5217193
The Morrison School of Agribusiness at Arizona State University leads research that bridges agricultural economics, behavioral science, and market analysis—providing insights that inform agribusiness strategy and public policy.